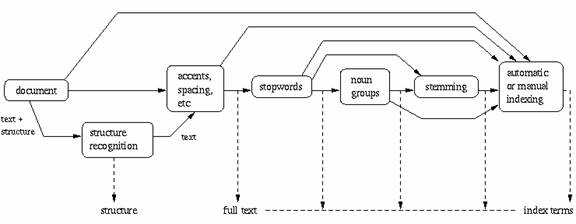
Figure: The process of retrieving information
Information Extraction (Information Retrieval)
A starting point for computers to analyze unstructured text is to use information
extraction. Information extraction software identifies key phrases and relationships within text. It does this by looking for predefined sequences in text, a process called pattern matching. For example, given the sentence “Area relatives of a man being held hostage in Iraq waited for word about him Saturday as militants threatened to decapitate him, another American and a Brit unless demands were met within 48 hours”, information extraction software should identify two American hostages and a British hostage, militants, and the relatives of one of the hostages as people; Iraq as the place; and Saturday as the time. The software infers the relationships between all the identified people, places, and time to provide the user with meaningful information. This technology can be very useful when dealing with large volumes of text. Almost all text mining software uses information extraction since it is the basis for many of the other
technologies discussed below. In our project we would be using Information Extraction to analyze our huge collection of unstructured text. So that it may be ready for further operations to be performed on it.
Summarization
Text summarization is immensely helpful for trying to figure out whether or not a
lengthy document meets the user’s needs and is worth reading for further information. With large texts, text summarization software processes and summarizes the document in the time it would take the user to read the first paragraph. The key to summarization is to reduce the length and detail of a document while retaining its main points and overall meaning. The challenge is that, although computers are able to identify people, places, and time, it is still difficult to teach software to analyze semantics and to interpret meaning. Generally, when humans summarize text, we read the entire selection to
©2005 Jatit